
MySQL╦„ę²Č©┴xŻ║╦„ę²Ż©IndexŻ® ╩ŪÄ═ų·MySQLĖ▀ą¦½@╚ĪöĄō■Ą─öĄō■ĮYśŗĪŻ ╠ß╚ĪŠõūėų„Ė╔Ż¼ Š═┐╔ęįĄ├ĄĮ╦„ę²Ą─▒Š┘|Ż║ ╦„ę²╩ŪöĄō■ĮYśŗĪŻ
┤¾▓┐ĘųöĄō■ÄņŽĄĮy╝░╬─╝■ŽĄĮyČ╝▓╔ė├B-Tree╗“ŲõūāĘNB+Treeū„×ķ╦„ę²ĮYśŗ
öĄō■ĮYśŗŠ▀¾wæ¬ė├ł÷Š░Ż║
öĄō■Äņ╩Ū╚ń║╬ū÷ĄĮ┐ņ╦┘Öz╦„Ą─╣”─▄ĪŻ
╠žäeėąęŌ╦╝Ą─ąĪ└²ūėĪŻ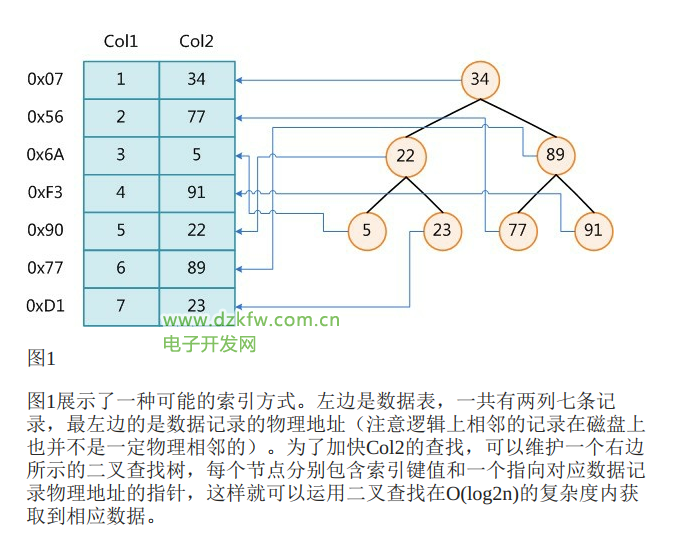
mysql╦„ę²įŁ└ĒĄ─└ĒĮŌ║═öĄō■ĮYśŗ
öĄō■ĮYśŗ
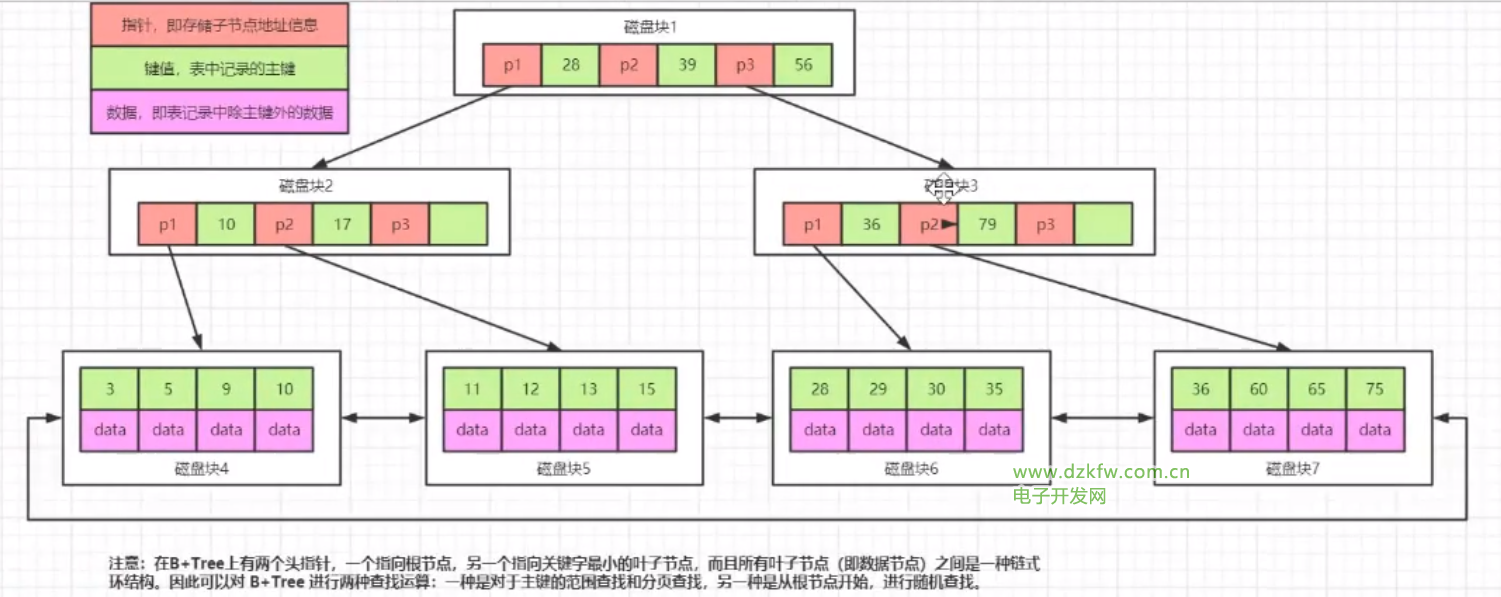
B+śõŻ©×ķ╩▓├┤╩╣ė├B+öĄŻ®
- ╦∙ėąöĄō■Č╝┤µā”į┌┤┼▒PųąŻ¼ūx╚ĪöĄō■ė╔ė┌IOå¢Ņ}Ģ■ūx╚Ī┬²Ż¼╚ń║╬╝ė┐ņIO╦┘Č╚
IO
- ┴┐Ż║£p╔┘IO┴┐
*Į¹ų╣╩╣ė├slect Ż¼▒▄├Ōį÷╝ė▓╗▒žę¬Ą─┴┐ - ┤╬öĄŻ║£p╔┘IO┤╬öĄ
ŽÓĻPų¬ūR³c
- ╝ė╚ļ╦„ę²Ż©╝ė┐ņ▓ķįā╦┘Č╚Ż®
- öĄō■ĮYśŗįOėŗŻ║keyĪó╬─╝■ŠÄ╠¢Īó«öŪ░╬─╝■Ą─offsetŻ©┤µį┌å¢Ņ}Ż║«ööĄō■┴┐╠žäe┤¾ĢrŻ¼╦„ę²╦∙š╝ė├Ą─┤µā”┐šķgę▓╠žäe┤¾ĪŻŻ®
- ĮŌøQĘĮĘ©Ż║╦„ę²Ą─öĄō■╬─╝■ę▓ąĶę¬│ųŠ├╗»┤µā”ĄĮ┤┼▒PųąŻ¼«öąĶę¬╩╣ė├Ģrų▒Įėūx╚ĪĄĮā╚┤µųąŻ¼╝ė┐ņöĄō■Ą─įLå¢Ż©ĘųČ°ų╬ų«Ż║ĘųēKūx╚ĪŻ®
- ▓┘ū„ŽĄĮy╗∙▒ŠĖ┼─ŅŻ║
1.Šų▓┐ąįįŁ└ĒŻ║öĄō■║═│╠ą“Č╝ėąŠ█╝»│╔╚║Ą─āAŽ“Ż¼ų«Ū░▒╗▓ķįā▀^Ą─öĄō■║▄┐ņĢ■į┘┤╬▒╗▓ķįāĪŻ└õ¤ßöĄō■Ż©ę╗╝ēŠÅ┤µŻ¼Č■╝ēŠÅ┤µĄ─ęŌ╦╝Ż®
2.┤┼▒PŅAūxŻ║į┌öĄō■Į╗ōQĢrŻ¼Ģ■ėąę╗éĆ╗∙▒Š▀ē▌ŗå╬╬╗ĒōŻ¼ę╗░Ńš╝ė├┐šķg╩Ū4kŻ¼├┐┤╬į┌▀MąąöĄō■½@╚ĪĢr┐╔ęį½@╚Īš¹ĒōĄ─š¹öĄ▒ČĪŻŻ©mysqlųąinnodbĄ─┤µā”ę²Ūµūx╚ĪöĄō■Ģ■ūx╚Ī16k show variables like Ī«%innodbĪ»Ż®
ket-valueĖ±╩ĮöĄō■ĮYśŗ┤µā”Ż║
- ╣■ŽŻ▒Ē
- śõŻ©Č■▓µśõĪóBSTĪóAVLĪó╝t║┌śõĪóBśõĪóB+śõŻ®
Č■Ęųų¦Ą─╚▒³cŻ║╔ŅČ╚╠½╔ŅŻ¼ĮŌøQĘĮĘ©Ż║BśõŻ©ČÓ▓µśõŻ®
Bśõ
- ╦č╦„śõ
- ČÓ╣سcČÓĘųų¦Ą─öĄ
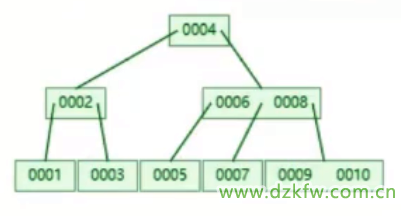
å¢Ņ}Ż║╝┘įO┤┼▒PēK┤µĘ┼16ŚlöĄō■Ż¼╚ń╣¹╩Ū╚²īėśõŻ¼ūŅČÓ┤µĘ┼Ą─öĄō■Ż║161616=4096Ż¼╝┤48k▓┼┤µĘ┼4096ŚlöĄō■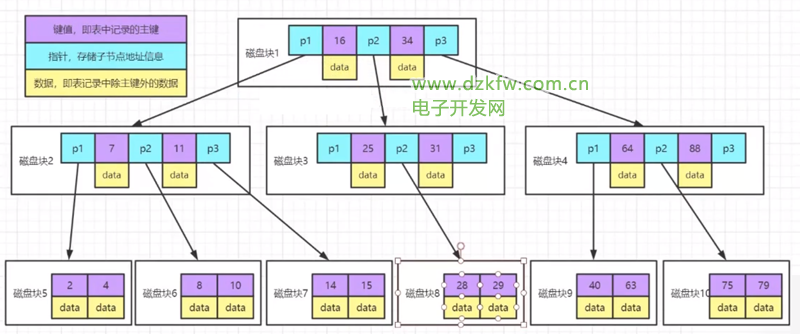
BöĄ┤µį┌å¢Ņ}Ż║┤µĘ┼┴╦öĄō■Ż¼ę└╚╗š╝ė├┐šķgŻ¼╚ń║╬£p╔┘öĄō■Ż¼ąĶę¬ė├ĄĮB+öĄ
B+śõ
- ūŅŽ┬├µĄ─╚~ūė╣سc┤µĘ┼Ą─╩ŪĒśą“╚½┴┐öĄō■
- ĘŪ╚~ūė╣سc┐╔ęį▓╗ė├┤µĘ┼data
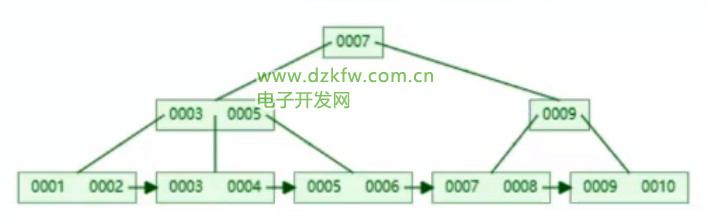
- å¢Ņ}Ż║ūx╚ĪöĄō■Ż¼╝┘įO╚²īėśõ48k┤┼▒PēKŻ¼1000ūų╣Ø×ķ1kbŻ¼ųĖßś║═µIųĄš╝10ūų╣ØŻ¼1ąąėøõø1k 161000/10=160016001600=40960000Ą─öĄō■ĘČć·Ż¼╝┤KeyµIųĄŻ¼ūŅŽ┬├µĄ─ų╗┤µĘ┼ę╗▒ķöĄō■*
- Į©╦„ę²ĢrŻ¼keyę¬▒M┐╔─▄╔┘Ą─š╝ė├┐šķg
╦„ę²╝╝ąg├¹į~
**╗ž▒ĒŻ║**Å─ĘŪŠ█┤ž╦„ę²╠°▐DĄĮŠ█┤ž╦„ę²ųą▓ķšęöĄō■Ą─▀^│╠Ż©▒▄├Ō╗ž▒Ē▓┘ū„select * from table Ż®
╦„ę²Ė▓╔w«öĘŪŠ█┤ž╦„ę²Ą─╚~ūė╣سcųą░³║¼┴╦▓ķįāąĶꬥ─╦∙ėąūųČ╬ĢrŻ¼▓╗ąĶę¬╗ž▒ĒĄ─▀^│╠Ż©═Ų╦]╩╣ė├select id,name from table Ż®
ūŅū¾Ųź┼õ:Īó╦„ę²Ž┬═Ų
 ĘĄ╗žĒö▓┐
ĘĄ╗žĒö▓┐ ╦óą┬Ēō├µ
╦óą┬Ēō├µ Ž┬ĄĮĒōĄū
Ž┬ĄĮĒōĄū