
CšZčįļmšfĮø│Ż║═C++į┌ę╗Ų▒╗┤¾╝ę╠ßŲŻ¼Ą½┐╔Ū¦╚f▓╗ę¬ęį×ķ╦³éā╩Ūę╗ĘNŠÄ│╠šZčįĪŻ╬ęéāüĒĮķĮBCšZčį║═C++ųąĄ─ģ^äe║═┬ōŽĄĪŻ
╩ūŽ╚C++║═CšZčį▒ŠüĒŠ═╩Ūā╔ĘN▓╗═¼Ą─ŠÄ│╠šZčįŻ¼Ą½C++┤_īŹ╩Ūī”CšZčįĄ─öU│õ║═čė╔ņŻ¼▓óŪęī”CšZčį╠ß╣®║¾Ž“╝µ╚▌Ą──▄┴”ĪŻ
Ė³ČÓCšZčį/C++īW┴Ģ┘Y┴ŽŻ¼ęĢŅlŻ¼ļŖūėĢ°╝«Ż¼Į╠│╠
ę╗ĪóCšZčį╩Ū├µŽ“▀^│╠šZčįŻ¼Č°C++╩Ū├µŽ“ī”Ž¾šZčį
╬ęéāČ╝ų¬Ą└CšZčį╩Ū├µŽ“▀^│╠šZčįŻ¼Č°C++╩Ū├µŽ“ī”Ž¾šZčįŻ¼šfCšZčį║═C++Ą─ģ^äe║═┬ōŽĄŻ¼ę▓Š═╩Ūį┌▒╚▌^├µŽ“▀^│╠║═├µŽ“ī”Ž¾Ą─ģ^äeĪŻ
1Īó├µŽ“▀^│╠║═├µŽ“ī”Ž¾Ą─ģ^äe
├µŽ“▀^│╠Ż║├µŽ“▀^│╠ŠÄ│╠Š═╩ŪĘų╬÷│÷ĮŌøQå¢Ņ}Ą─▓Į¾EŻ¼╚╗║¾░č▀@ą®▓Į¾Eę╗▓Įę╗▓ĮĄ─īŹ¼FŻ¼╩╣ė├Ą─Ģr║“ę╗éĆę╗éĆĄ─ę└┤╬š{ė├Š═┐╔ęį┴╦ĪŻ
├µŽ“ī”Ž¾Ż║├µŽ“ī”Ž¾ŠÄ│╠Š═╩Ū░čå¢Ņ}ĘųĮŌ│╔Ė„éĆī”Ž¾Ż¼Į©┴óī”Ž¾Ą──┐Ą─▓╗╩Ū×ķ┴╦═Ļ│╔ę╗éĆ▓Į¾EŻ¼Č°╩Ū×ķ┴╦├Ķ╩÷─│éĆ╩┬╬’į┌š¹éĆĮŌøQå¢Ņ}Ą─▓Į¾EųąĄ─ąą×ķĪŻ
2Īó├µŽ“▀^│╠║═├µŽ“ī”Ž¾Ą─ā×╚▒³c
į┌īW┴Ģę╗ą®▒╚▌^│ķŽ¾Ą─Ė┼─ŅĢrŻ¼ė╔ė┌╬ęéāĄ─└ĒĮŌ─▄┴”║▄ėąŽ▐Ż¼ėąĢr║“ę╗ą®▒╚▌^ŪĪ«öĄ─└²ūėę▓╩Ūėąų·ė┌╬ęéāīW┴ĢĄ─Ż¼ę“┤╦ī”Č■š▀Ą─ā×╚▒³c▒╚▌^Ż¼▀Ć╩ŪŽ╚┼e└²ūėŻ¼║¾┐éĮY░╔ŻĪ
Ż©1Ż®ė├├µŽ“▀^│╠īæ│÷üĒĄ─│╠ą“Š═Ž±ę╗Ę▌Ą░│┤’łŻ¼ę▓Š═╩Ū├ū’ł║═│┤Ą─▓╦Š∙ä“Ą─╗ņ║Žį┌┴╦ę╗ŲŻ¼ę“┤╦Ą░│┤’ł╚ļ╬ČŠ∙ä“Ż¼▓╗Ģ■Ž±╔wØ▓’ł─ŪśėŻ¼┐╔─▄ėąĢr║“│įĄ─▓╦ČÓ’ł╔┘Ż¼▀ĆėąĢr║“▓╦╔┘’łČÓĪŻĄ½╩Ū╚ń╣¹─Ń▓╗Ž▓Üg│įĄ░│┤’łŻ¼ų╗Žļ│į╚Ō│┤’łŻ¼─Ū├┤įŁüĒū÷Ą─▀@Ę▌Ą░│┤’łŠ═Ą├Ą╣Ą¶┴╦Ż¼ųžą┬ū÷ę╗Ę▌╚Ō│┤’łŻ¼ÅNĤŠ═Ą├ą┴┐Ó┴╦ŻĪ
Ż©2Ż®ė├├µŽ“ī”Ž¾īæ│÷üĒĄ─│╠ą“Š═Ž±ę╗Ę▌╔wØ▓’łŻ¼ę▓Š═╩Ū├ū’ł║═╔w▓╦Ęųäeū÷║├Ż¼īó╔w▓╦Ę┼į┌├ū’ł╔Ž├µŻ¼╔wØ▓’łļm╚╗ø]ėąĄ░│┤’ł─Ūśė╚ļ╬ČŠ∙ä“Ż¼Ą½╩Ū╚ń╣¹Įo┴╦─Ńę╗Ę▌═┴Č╣Įz╔w’łŻ¼─Ńėų▓╗Žļ│į┴╦Ż¼ōQ│╔┼Ż╚Ō╔w’łŻ¼ÅNĤų╗ąĶę¬īó├ū’ł╔Ž├µĄ─═┴Č╣ĮzĄ╣Ą¶Ż¼ųžą┬ū÷ę╗Ę▌┼Ż╚ŌĘ┼į┌╔Ž├µŠ═║├┴╦ĪŻ
─Ū├┤ĄĮĄūĄ░│┤’ł║═╔wØ▓’ł──éĆ║├│į─žŻ┐
šlę▓▓╗─▄šfĄĮĄū──éĆ║├Ż¼«ģŠ╣Ą░│┤’łĄ─▓═^║═╔wØ▓’łĄ─▓═^Č╝║▄ČÓŻ¼Č°Ūę╔·ęŌČ╝║▄▓╗ÕeŻ¼┤µį┌╝┤×ķ║Ž└ĒŻĪ
╚ń╣¹ĘŪę¬īóČ■š▀▀Mąąę╗éĆĖ▀ĄžĄ─▒╚▌^Ą─įÆŻ¼─ŪŠ═Ą├Ž╚įOČ©ę╗éĆł÷Š░┴╦ŻĪ
╔wØ▓’łĄ─║├╠ÄŠ═╩ŪĪ▒▓╦Ī▒Ī░’łĪ▒ĘųļxŻ¼Å─Č°╠ßĖ▀┴╦ųŲū„╔wØ▓’łĄ─ņ`╗ŅąįĪŻ’ł▓╗ØMęŌŠ═ōQ’łŻ¼▓╦▓╗ØMęŌōQ▓╦ĪŻė├īŻśIągšZüĒšfŠ═╩ŪĪ▒┐╔ŠSūoąįĪ░▌^║├Ż¼Ī▒’łĪ▒ ║═Ī▒▓╦Ī▒Ą─±Ņ║ŽČ╚▒╚▌^Ą═ĪŻ
Ą░│┤’łīóĪ▒Ą░Ī▒Ī░’łĪ▒öć║═į┌ę╗ŲŻ¼ŽļōQĪ▒Ą░Ī▒Ī░’łĪ▒ųą╚╬║╬ę╗ĘNČ╝║▄└¦ļyŻ¼±Ņ║ŽČ╚║▄Ė▀Ż¼ęįų┴ė┌Ī▒┐╔ŠSūoąįĪ▒▒╚▌^▓ŅĪŻ
Č■š▀Ą─║åå╬┐éĮY╚ńŽ┬Ż║
├µŽ“▀^│╠šZčį
ā׳cŻ║ąį─▄▒╚├µŽ“ī”Ž¾Ė▀Ż¼ę“×ķŅÉš{ė├ĢrąĶę¬īŹ└²╗»Ż¼ķ_õN▒╚▌^┤¾Ż¼▒╚▌^Ž¹║─┘Yį┤;▒╚╚ńå╬Ų¼ÖCĪóŪČ╚ļ╩Įķ_░lĪó Linux/UnixĄ╚ę╗░Ń▓╔ė├├µŽ“▀^│╠ķ_░lŻ¼ąį─▄╩ŪūŅųžę¬Ą─ę“╦žĪŻ
╚▒³cŻ║ø]ėą├µŽ“ī”Ž¾ęūŠSūoĪóęūÅ═ė├ĪóęūöUš╣
├µŽ“ī”Ž¾šZčįŻ║
ā׳cŻ║ęūŠSūoĪóęūÅ═ė├ĪóęūöUš╣Ż¼ė╔ė┌├µŽ“ī”Ž¾ėąĘŌčbĪó└^│ąĪóČÓæBąįĄ─╠žąįŻ¼┐╔ęįįOėŗ│÷Ą═±Ņ║ŽĄ─ŽĄĮyŻ¼╩╣ŽĄĮy Ė³╝ėņ`╗ŅĪóĖ³╝ėęūė┌ŠSūo
╚▒³cŻ║ąį─▄▒╚├µŽ“▀^│╠Ą═
Č■ĪóŠ▀¾wšZčį╔ŽCšZčį║═C++Ą─ģ^äe║═┬ōŽĄ
1ĪóĻPµIūųĄ─▓╗═¼
CšZčįėą32éĆĻPµIūų
C++ėą63éĆĻPµIūų
2Īó║¾ŠY├¹▓╗═¼
Cį┤╬─╝■║¾ŠY.cŻ¼C++į┤╬─╝■║¾ŠY.cppŻ¼į┌VSųąŻ¼╚ń╣¹į┌äōĮ©į┤╬─╝■Ģr╩▓├┤Č╝▓╗ĮoŻ¼─¼šJ╩Ū.cppĪŻ
3ĪóĘĄ╗žųĄ
CšZčįųąŻ¼╚ń╣¹ę╗éĆ║»öĄø]ėąųĖČ©ĘĄ╗žųĄŅÉą═Ż¼─¼šJĘĄ╗žintŅÉą═Ż╗C++ųąŻ¼╚ń╣¹ę╗éĆ║»öĄø]ėąĘĄ╗žųĄät▒žĒÜųĖČ©×ķvoidĪŻ
4ĪóģóöĄ┴ą▒Ē
į┌CšZčįųąŻ¼║»öĄø]ėąųĖČ©ģóöĄ┴ą▒ĒĢrŻ¼─¼šJ┐╔ęįĮė╩š╚╬ęŌČÓéĆģóöĄŻ╗Ą½į┌C++ųąŻ¼ę“×ķć└Ė±Ą─ģóöĄŅÉą═Öz£yŻ¼ø]ėąģóöĄ┴ą▒ĒĄ─║»öĄŻ¼─¼šJ×ķ voidŻ¼▓╗Įė╩š╚╬║╬ģóöĄĪŻ
5Īó╚▒╩ĪģóöĄ
╚▒╩ĪģóöĄ╩Ū┬Ģ├„╗“Č©┴x║»öĄĢr×ķ║»öĄĄ─ģóöĄųĖČ©ę╗éĆ─¼šJųĄĪŻį┌š{ė├įō║»öĄĢrŻ¼╚ń╣¹ø]ėąųĖČ©īŹģóät▓╔ė├įō─¼šJųĄŻ¼Ę±ät╩╣ė├ųĖČ©Ą─ģóĪŻŻ©CšZčį▓╗ų¦│ų╚▒╩ĪģóöĄŻ®
ūóęŌŻ║
-
į┌░ļ╚▒╩ĪĄ─ŪķørŽ┬Ż¼Ä¦╚▒╩ĪųĄĄ─ģóöĄ▒žĒÜĘ┼į┌ģóöĄ┴ą▒ĒĄ─ūŅ║¾├µĪŻ
-
╚▒╩ĪģóöĄ▓╗─▄═¼Ģrį┌║»öĄĄ─┬Ģ├„║═║»öĄČ©┴xųą│÷¼FŻ¼Č■š▀ų╗─▄▀xŲõę╗ĪŻ
-
╚▒╩ĪųĄ▒žĒÜ╩Ū│Ż┴┐╗“š▀╚½Šųūā┴┐ĪŻ
-
╚▒╩ĪģóöĄ▒žĒÜ═©▀^ųĄģó╗“│Żģóé„▀fĪŻ
6Īó║»öĄųž▌d
║»öĄųž▌dŻ║║»öĄųž▌d╩Ū║»öĄĄ─ę╗ĘN╠ž╩ŌŪķørŻ¼ųĖį┌═¼ę╗ū„ė├ė“ųąŻ¼┬Ģ├„ÄūéĆ╣”─▄ŅÉ╦ŲĄ─═¼├¹║»öĄŻ¼▀@ą®═¼├¹║»öĄĄ─ą╬ģó┴ą▒ĒŻ©ģóöĄéĆöĄĪóŅÉą═ĪóĒśą“Ż®▒žĒÜ▓╗═¼Ż¼ĘĄ╗žųĄŅÉą═┐╔ęįŽÓ═¼ę▓┐╔ęį▓╗═¼Ż¼│Żė├üĒ╠Ä└ĒīŹ¼F╣”─▄ŅÉ╦ŲöĄō■ŅÉą═▓╗═¼Ą─å¢Ņ}ĪŻŻ©CšZčįø]ėą║»öĄųž▌dŻ¼C++ų¦│ų║»öĄųž▌dŻ®ĪŻ
CšZčįųą«a╔·║»öĄĘ¹╠¢Ą─ęÄät╩ŪĖ∙ō■├¹ĘQ«a╔·Ż¼▀@ę▓Š═ūóČ©┴╦cšZčį▓╗┤µį┌║»öĄųž▌dĄ─Ė┼─ŅĪŻČ°C++╔·│╔║»öĄĘ¹╠¢ät┐╝æ]┴╦║»öĄ├¹ĪóģóöĄéĆöĄĪóģóöĄŅÉą═ĪŻąĶę¬ūóęŌĄ─╩Ū║»öĄĄ─ĘĄ╗žųĄ▓ó▓╗─▄ū„×ķ║»öĄųž▌dĄ─ę└ō■Ż¼ę▓Š═╩Ūšfint sum║═double sum▀@ā╔éĆ║»öĄ╩Ū▓╗─▄śŗ│╔ųž▌dĄ─ŻĪ
╬ęéāĄ─║»öĄųž▌dę▓ī┘ė┌ČÓæBĄ─ę╗ĘNŻ¼▀@Š═╩Ū╦∙ų^Ą─ņoČÓæBĪŻ
ņoČÓæBŻ║║»öĄųž▌dŻ¼║»öĄ─Ż░Õ
äėČÓæBŻ©▀\ąąĢrĄ─ČÓæBŻ®Ż║└^│ąųąĄ─ČÓæBŻ©╠ō║»öĄŻ®ĪŻ
╩╣ė├ųž▌dĄ─Ģr║“ąĶę¬ūóęŌū„ū„ė├ė“å¢Ņ}Ż║šł┐┤╚ńŽ┬┤·┤aĪŻ
#includeusing namespace std; bool compare(int a,int b) { return a > b; } bool compare(double a,double b) { return a > b; } int main() { //bool compare(int a,int b); compare(10,20); compare(10.5,20.5); return 0; }
╬ęį┌╚½Šųū„ė├ė“Č©┴x┴╦ā╔éĆ║»öĄŻ¼╦³éāė╔ė┌ģóöĄŅÉą═▓╗═¼┐╔ęįśŗ│╔ųž▌dŻ¼┤╦Ģrmain║»öĄųąš{ė├ät┐╔ęįš²┤_Ą─š{ė├ĄĮĖ„ūįĄ─║»öĄĪŻ
Ą½╩Ūšł┐┤main║»öĄųą▒╗ūóßīĄ¶Ą─ę╗Šõ┤·┤aĪŻ╚ń╣¹╬ęīó╦³Ę┼│÷üĒŻ¼ätĢ■╠ß│÷Š»ĖµŻ║īódoubleŅÉą═▐DōQ│╔intŅÉą═┐╔─▄Ģ■üG╩¦öĄō■ĪŻ
▀@Š═ęŌ╬Čų°╬ęéāŠÄūgŲ„ßśī”Ž┬├µā╔Šõš{ė├Č╝š{ė├┴╦ģóöĄŅÉą═intĄ─compareĪŻė╔┤╦┐╔ęŖŻ¼ŠÄūgŲ„š{ė├║»öĄĢrā׎╚į┌Šų▓┐ū„ė├ė“╦č╦„Ż¼╚¶╦č╦„│╔╣”ät╚½▓┐░┤ššįō║»öĄĄ─ś╦£╩š{ė├ĪŻ╚¶╬┤╦č╦„ĄĮ▓┼į┌╚½Šųū„ė├ė“▀Mąą╦č╦„ĪŻ
┐éĮYŻ║CšZčį▓╗┤µį┌║»öĄųž▌dŻ¼C++Ė∙ō■║»öĄ├¹ģóöĄéĆöĄģóöĄŅÉą═┼ąöÓųž▌dŻ¼ī┘ė┌ņoČÓæBŻ¼▒žĒÜ═¼ę╗ū„ė├ė“Ž┬▓┼Įąųž▌dĪŻ
7Īóconst
CšZčįųą▒╗constą▐’ŚĄ─ūā┴┐▓╗╩Ū│Ż┴┐Ż¼Įąū÷│Żūā┴┐╗“š▀ų╗ūxūā┴┐Ż¼▀@éĆ│Żūā┴┐╩Ū¤oĘ©«öū„öĄĮMŽ┬ś╦Ą─ĪŻ╚╗Č°į┌C++ųąconstą▐’ŚĄ─ūā┴┐┐╔ęį«öū„öĄĮMŽ┬ś╦╩╣ė├Ż¼│╔×ķ┴╦šµš²Ą─│Ż┴┐ĪŻ▀@Š═╩ŪC++ī”constĄ─öUš╣ĪŻ
CšZčįųąĄ─constŻ║▒╗ą▐’Ś║¾▓╗─▄ū÷ū¾ųĄŻ¼┐╔ęį▓╗│§╩╝╗»Ż¼Ą½╩Ūų«║¾ø]ėąÖCĢ■į┘│§╩╝╗»ĪŻ▓╗┐╔ęį«ööĄĮMĄ─Ž┬ś╦Ż¼┐╔ęį═©▀^ųĖßśą▐Ė─ĪŻ║åå╬üĒšfŻ¼╦³║═Ųš═©ūā┴┐Ą─ģ^äeų╗╩Ū▓╗─▄ū÷ū¾ųĄČ°ęčĪŻŲõ╦¹ĄžĘĮČ╝╩Ūę╗śėĄ─ĪŻ
C++ųąĄ─constŻ║šµš²Ą─│Ż┴┐ĪŻČ©┴xĄ─Ģr║“▒žĒÜ│§╩╝╗»Ż¼┐╔ęįė├ū„öĄĮMĄ─Ž┬ś╦ĪŻconstį┌C++ųąĄ─ŠÄūgęÄät╩Ū╠µōQŻ©║═║Ļ║▄Ž±Ż®Ż¼╦∙ęį╦³▒╗┐┤ū„╩Ūšµš²Ą─│Ż┴┐ĪŻę▓┐╔ęį═©▀^ųĖßśą▐Ė─ĪŻąĶę¬ūóęŌĄ─╩ŪŻ¼C++Ą─ųĖßśėą┐╔─▄═╦╗»│╔CšZčįĄ─ųĖßśĪŻ▒╚╚ńęįŽ┬ŪķørŻ║
int b=20; const int a = b;
▀@Ģr║“Ą─aŠ═ų╗╩Ūę╗éĆŲš═©Ą─CšZčįĄ─const│Żūā┴┐┴╦Ż¼ęčĮø¤oĘ©«ööĄĮMĄ─Ž┬ś╦┴╦ĪŻŻ©ę²ė├┴╦ę╗éĆŠÄūgļAČ╬▓╗┤_Č©Ą─ųĄŻ®
constį┌╔·│╔Ę¹╠¢ĢrŻ¼╩ŪlocalĘ¹╠¢ĪŻ╝┤į┌▒Š╬─╝■ųą▓┼┐╔ęŖĪŻ╚ń╣¹ĘŪę¬į┌äeĄ─╬─╝■ųą╩╣ė├╦³Ą─įÆŻ¼į┌╬─╝■Ņ^▓┐┬Ģ├„Ż║extern cosnt int data = 10Ż╗▀@śė╔·│╔Ą─Ę¹╠¢Š═╩ŪglobalĘ¹╠¢ĪŻ
┐éĮYŻ║CųąĄ─constĮąų╗ūxūā┴┐Ż¼ų╗╩Ū¤oĘ©ū÷ū¾ųĄĄ─ūā┴┐Ż╗C++ųąĄ─const╩Ūšµš²Ą─│Ż┴┐Ż¼Ą½ę▓ėą┐╔─▄═╦╗»│╔cšZčįĄ─│Ż┴┐Ż¼─¼šJ╔·│╔localĘ¹╠¢ĪŻ
8Īóę²ė├
šfĄĮę²ė├Ż¼╬ęéāĄ┌ę╗Ę┤權═╩ŪŽļĄĮ┴╦╦¹Ą─ąųĄ▄Ż║ųĖßśĪŻę²ė├Å─ĄūīėüĒšf║═ųĖßśŠ═╩Ū═¼ę╗éĆ¢|╬„Ż¼Ą½╩Ūį┌ŠÄūgŲ„ųą╦³Ą─╠žąį║═ųĖßś═Ļ╚½▓╗═¼ĪŻ
int a = 10; int &b=a; int *p = &a; // b = 20; // *p=20;
╩ūŽ╚Č©┴xę╗éĆūā┴┐a = 10Ż¼╚╗║¾╬ęéāĘųäeČ©┴xę╗éĆę²ė├bęį╝░ę╗éĆųĖßśpųĖŽ“aĪŻ╬ęéāüĒ▐DĄĮĘ┤ģRŠÄ┐┤┐┤ĄūīėĄ─īŹ¼FŻ║
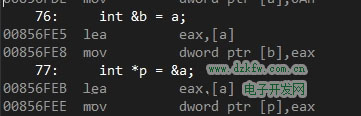
┐╔ęį┐┤ĄĮĄūīėīŹ¼F═Ļ╚½ę╗ų┬Ż¼╚ĪaĄ─ĄžųĘĘ┼╚ļeax╝─┤µŲ„Ż¼į┘īóeaxųąĄ─ųĄ┤µ╚ļę²ė├b/ųĖßśpĄ─ā╚┤µųąĪŻų┴┤╦╬ęéā┐╔ęįšfŻ©į┌ĄūīėŻ®ę²ė├▒Š┘|Š═╩Ūę╗éĆųĖßśĪŻ
┴╦ĮŌ┴╦ĄūīėīŹ¼FŻ¼╬ęéā╗žĄĮŠÄūgŲ„ĪŻ╬ęéā┐┤ĄĮī”aĄ─ųĄĄ─ą▐Ė─Ż¼ųĖßśpĄ─ū÷Ę©╩Ū*p = 20Ż╗╝┤▀MąąĮŌę²ė├║¾╠µōQųĄĪŻĄūīėīŹ¼FŻ║
į┘üĒ┐┤┐┤ę²ė├ą▐Ė─Ż║
╬ęéā┐┤ĄĮą▐Ė─aĄ─ųĄĄ─ĘĮĘ©ę▓╩Ūę╗śėĄ─Ż¼ę▓╩ŪĮŌę²ė├ĪŻų╗╩Ū╬ęéāį┌š{ė├Ą─Ģr║“ėą╦∙▓╗═¼Ż║š{ė├pĢrąĶę¬*pĮŌę²ė├Ż¼bätų▒Įė╩╣ė├Š═┐╔ęįĪŻė╔┤╦╬ęéā ═ŲöÓ│÷Ż║ę²ė├į┌ų▒Įė╩╣ė├Ģr╩ŪųĖßśĮŌę²ė├ĪŻpų▒Įė╩╣ė├ät╩Ū╦³ūį╝║Ą─ĄžųĘĪŻ
▀@śė╬ęéāę▓┴╦ĮŌ┴╦Ż¼╬ęéāĮoę²ė├ķ_▒┘Ą─▀@ēKā╚┤µ╩ŪĖ∙▒ŠįLå¢▓╗ĄĮĄ─ĪŻ╚ń╣¹ų▒Įėė├Š═ų▒ĮėĮŌę²ė├┴╦ĪŻ╝┤╩╣┤“ėĪ&bŻ¼▌ö│÷Ą─ę▓╩ŪaĄ─ĄžųĘĪŻ
į┌┤╦ĖĮ╔ŽīóųĖßś▐D×ķę²ė├Ą─ąĪ╝╝Ū╔Ż║int *p = &a,╬ęéāīó ę²ė├Ę¹╠¢ęŲĄĮū¾▀ģ īó *╠µōQ╝┤┐╔Ż║int &p = aĪŻ
ĮėŽ┬üĒ┐┤┐┤╚ń║╬äōĮ©öĄĮMĄ─ę²ė├Ż║
int array[10] = {0}Ż╗ //Č©┴xę╗éĆöĄĮM
╬ęéāų¬Ą└Ż¼array─├│÷üĒ╩╣ė├Ą─įÆŠ═╩ŪöĄĮMarrayĄ─╩ūį¬╦žĄžųĘĪŻ╝┤╩Ūint *ŅÉą═ĪŻ
─Ū├┤&array╩Ū╩▓├┤ęŌ╦╝─žŻ┐int **ŅÉą═Ż¼ė├üĒųĖŽ“array[0]ĄžųĘĄ─ę╗éĆĄžųĘå߯┐▓╗ꬎļ«ö╚╗┴╦Ż¼&array╩Ūš¹éĆöĄĮMŅÉą═ĪŻ
─Ū├┤ę¬Č©┴xę╗éĆöĄĮMę²ė├Ż¼░┤šš╔Ž├µĄ─ąĪįEĖ[Ż¼Ž╚üĒīæīæöĄĮMųĖßś░╔Ż║
int (*q) [10] = &array;
īóėęé╚Ą─&ī”ū¾▀ģĄ─*▀MąąĖ▓╔wŻ║
int (&q)[10] = array;
£yįćsizeof(q) = 10ĪŻ╬ęéā│╔╣”äōĮ©┴╦öĄĮMę²ė├ĪŻ
Įø▀^╔Ž├µĄ─įöĮŌ Ż¼╬ęéāų¬Ą└┴╦ę²ė├ŲõīŹŠ═╩Ū╚ĪĄžųĘĪŻ─Ū├┤╬ęéāČ╝ų¬Ą└ę╗éĆ┴ó╝┤öĄ╩Ūø]ėąĄžųĘĄ─Ż¼╝┤
int &b = 10;
▀@śėĄ─┤·┤a╩Ū¤oĘ©═©▀^ŠÄūgĄ─ĪŻ─Ū╚ń╣¹─ŃŠ═╩ŪĘŪę¬ę²ė├ę╗éĆ┴ó╝┤öĄŻ¼ŲõīŹę▓▓╗╩Ūø]ėą▐kĘ©Ż║
const int &b = 10Ż╗
╝┤īó▀@éĆ┴ó╝┤öĄė├constą▐’Śę╗Ž┬Ż¼Š═┐╔ęį┴╦ĪŻ×ķ╩▓├┤─žŻ┐
▀@Ģrę“×ķ▒╗constą▐’ŚĄ─Č╝Ģ■«a╔·ę╗éĆ┼RĢr┴┐üĒ▒Ż┤µ▀@éĆöĄō■Ż¼ūį╚╗Š═ėąĄžųĘ┐╔╚Ī┴╦ĪŻ
9Īómalloc,free && new,delete
▀@éĆå¢Ņ}║▄ėąęŌ╦╝Ż¼ę▓╩Ūųž³cąĶę¬ĻPūóĄ─å¢Ņ}ĪŻmalloc()║═free()╩ŪCšZčįųąäėæB╔Ļšłā╚┤µ║═ßīĘ┼ā╚┤µĄ─ś╦£╩ÄņųąĄ─║»öĄĪŻČ°new║═delete╩ŪC++▀\╦ŃĘ¹ĪóĻPµIūųĪŻnew║═deleteĄūīėŲõīŹ▀Ć╩Ūš{ė├┴╦malloc║═freeĪŻ╦³éāų«ķgĄ─ģ^äeėąęįŽ┬ÄūéĆĘĮ├µŻ║
1Ż®Īómalloc║═free╩Ū║»öĄŻ¼new║═delete╩Ū▀\╦ŃĘ¹ĪŻ
2Ż®Īómallocį┌Ęų┼õā╚┤µŪ░ąĶę¬┤¾ąĪŻ¼new▓╗ąĶę¬ĪŻ
└²╚ńŻ║int *p1 = (int *)malloc(sizeof(int));
int *p2 = new int; //int *p3 = new int(10);
mallocĢrąĶę¬ųĖČ©┤¾ąĪŻ¼▀ĆąĶę¬ŅÉą═▐DōQĪŻnewĢr▓╗ąĶę¬ųĖČ©┤¾ąĪę“×ķ╦³┐╔ęįÅ─Įo│÷Ą─ŅÉą═┼ąöÓŻ¼▓óŪę▀Ć┐╔ęį═¼Ģr┘x│§╩╝ųĄĪŻ
3Ż®Īómalloc▓╗░▓╚½Ż¼ąĶę¬╩ųäėŅÉą═▐DōQŻ¼new▓╗ąĶę¬ŅÉą═▐DōQĪŻ
įöęŖ╔Žę╗ŚlĪŻ
4Ż®Īófreeų╗ßīĘ┼┐šķgŻ¼deleteŽ╚š{ė├╬÷śŗ║»öĄį┘ßīĘ┼┐šķgŻ©╚ń╣¹ąĶ꬯®ĪŻ
┼cĄ┌ó▌Ślī”æ¬Ż¼╚ń╣¹╩╣ė├┴╦Å═ļsŅÉą═Ż¼Ž╚╬÷śŗį┘call operator delete╗ž╩šā╚┤µĪŻ
5Ż®Īónew╩ŪŽ╚š{ė├śŗįņ║»öĄį┘╔Ļšł┐šķgŻ©╚ń╣¹ąĶ꬯®ĪŻ
┼cĄ┌ó▄Ślī”æ¬Ż¼╬ęéāį┌š{ė├newĄ─Ģr║“Ż©└²╚ńint *p2 = new int;▀@Šõ┤·┤a Ż®Ż¼Ąūīė┤·┤aĄ─īŹ¼F╩ŪŻ║╩ūŽ╚push 4ūų╣ØŻ©intŅÉą═Ą─┤¾ąĪŻ®Ż¼ļS║¾call operator new║»öĄĘų┼õ┴╦ā╚┤µĪŻė╔ė┌╬ęéā▀@Šõ┤·┤a▓ó╬┤╔µ╝░ĄĮÅ═ļsŅÉą═Ż©╚ńŅÉŅÉą═Ż®Ż¼╦∙ęįę▓Š═ø]ėąśŗįņ║»öĄĄ─š{ė├ĪŻ╚ńŽ┬╩Ūoperator newĄ─į┤┤·┤aŻ¼ę▓╩ŪnewīŹ¼FĄ─ųžę¬║»öĄŻ║
void *__CRTDECL operator new(size_t size) _THROW1(_STD bad_alloc)
{ // try to allocate size bytes
void *p;
while ((p = malloc(size))==0)
if ( _callnewh(size)==0)
{
// report no memory
THROW_NCEE(_XSTD bad allocŻ¼);
}
return (p);
}
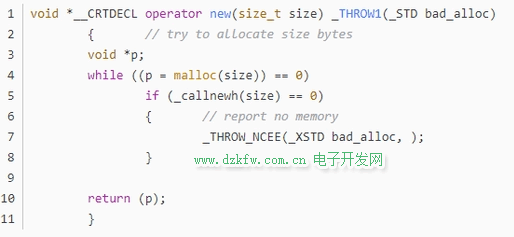
╬ęéā┐╔ęį┐┤ĄĮŻ¼╩ūŽ╚malloc(size)╔ĻšłģóöĄūų╣Ø┤¾ąĪĄ─ā╚┤µŻ¼╚ń╣¹╩¦öĪ(malloc╩¦öĪĘĄ╗ž0)ät▀M╚ļ┼ąöÓŻ║╚ń╣¹_callnewh(size)ę▓╩¦öĪĄ─įÆŻ¼Æü│÷bad_alloc«É│ŻĪŻ_callnewh()▀@éĆ║»öĄ╩Ūį┌▓ķ┐┤new handler╩Ūʱ┐╔ė├Ż¼╚ń╣¹┐╔ė├Ģ■ßīĘ┼ę╗▓┐Ęųā╚┤µį┘ĘĄ╗žĄĮmalloc╠Ä└^└m╔ĻšłŻ¼╚ń╣¹new handler▓╗┐╔ė├Š═Ģ■Æü│÷«É│ŻĪŻ
6Ż®Īóā╚┤µ▓╗ūŃŻ©ķ_▒┘╩¦öĪŻ®Ģr╠Ä└ĒĘĮ╩Į▓╗═¼ĪŻ
malloc╩¦öĪĘĄ╗ž0Ż¼new╩¦öĪÆü│÷bad_alloc«É│ŻĪŻ
7Ż®Īónew║═mallocķ_▒┘ā╚┤µĄ─╬╗ų├▓╗═¼ĪŻ
mallocķ_▒┘į┌Ččģ^Ż¼newķ_▒┘į┌ūįė╔┤µā”ģ^ė“ĪŻ
8Ż®Īónew┐╔ęįš{ė├malloc(),Ą½malloc▓╗─▄š{ė├newĪŻ
newŠ═╩Ūė├malloc()īŹ¼FĄ─Ż¼new╩ŪC++¬Üėąmalloc«ö╚╗¤oĘ©š{ė├ĪŻ
10Īóū„ė├ė“
CšZčįųąū„ė├ė“ų╗ėąā╔éĆŻ║Šų▓┐Ż¼╚½ŠųĪŻC++ųąät╩ŪėąŻ║Šų▓┐ū„ė├ė“Ż¼ŅÉū„ė├ė“Ż¼├¹ūų┐šķgū„ė├ė“╚²ĘNĪŻ
╦∙ų^├¹ūų┐šķgŠ═╩ŪnamespaceŻ¼╬ęéāČ©┴xę╗éĆ├¹ūų┐šķgŠ═╩ŪČ©┴xę╗éĆą┬ū„ė├ė“ĪŻįLå¢ĢrąĶę¬ęį╚ńŽ┬ĘĮ╩ĮįLå¢Ż©ęįstd×ķ└²Ż®
std::cin<< "123" <<std::endl;
└²╚ń╬ęéāėąę╗éĆ├¹ūų┐šķgĮąMynameŻ¼Ųõųąėąę╗éĆūā┴┐Įąū÷dataĪŻ╚ń╣¹╬ęéāŽŻ═¹į┌Ųõ╦¹ĄžĘĮ╩╣ė├dataĄ─įÆŻ¼ąĶę¬į┌╬─╝■Ņ^┬Ģ├„Ż║using Myname::dataŻ╗▀@śėę╗üĒdataŠ═╩╣ė├Ą─╩ŪMynameųąĄ─ųĄ┴╦ĪŻ┐╔╩Ū▀@śė├┐éĆĘ¹╠¢╬ęéāČ╝Ą├┬Ģ├„žM▓╗╩Ū└█╦└Ż┐
╬ęéāų╗ę¬using namespace MynameŻ╗Š═┐╔ęįīóŲõųą╦∙ėąĘ¹╠¢ī¦╚ļ┴╦ĪŻ
 ĘĄ╗žĒö▓┐
ĘĄ╗žĒö▓┐ ╦óą┬Ēō├µ
╦óą┬Ēō├µ Ž┬ĄĮĒōĄū
Ž┬ĄĮĒōĄū